R remains a strong choice when the work is heavy on statistics, exploratory analysis, reporting, and reproducible research. The ecosystem is no longer about finding one package that does everything well. It is about choosing a small set of packages that fit the workflow:
- data ingestion and cleanup
- analysis and visualization
- modeling and validation
- reproducible pipelines
- APIs or apps for delivery
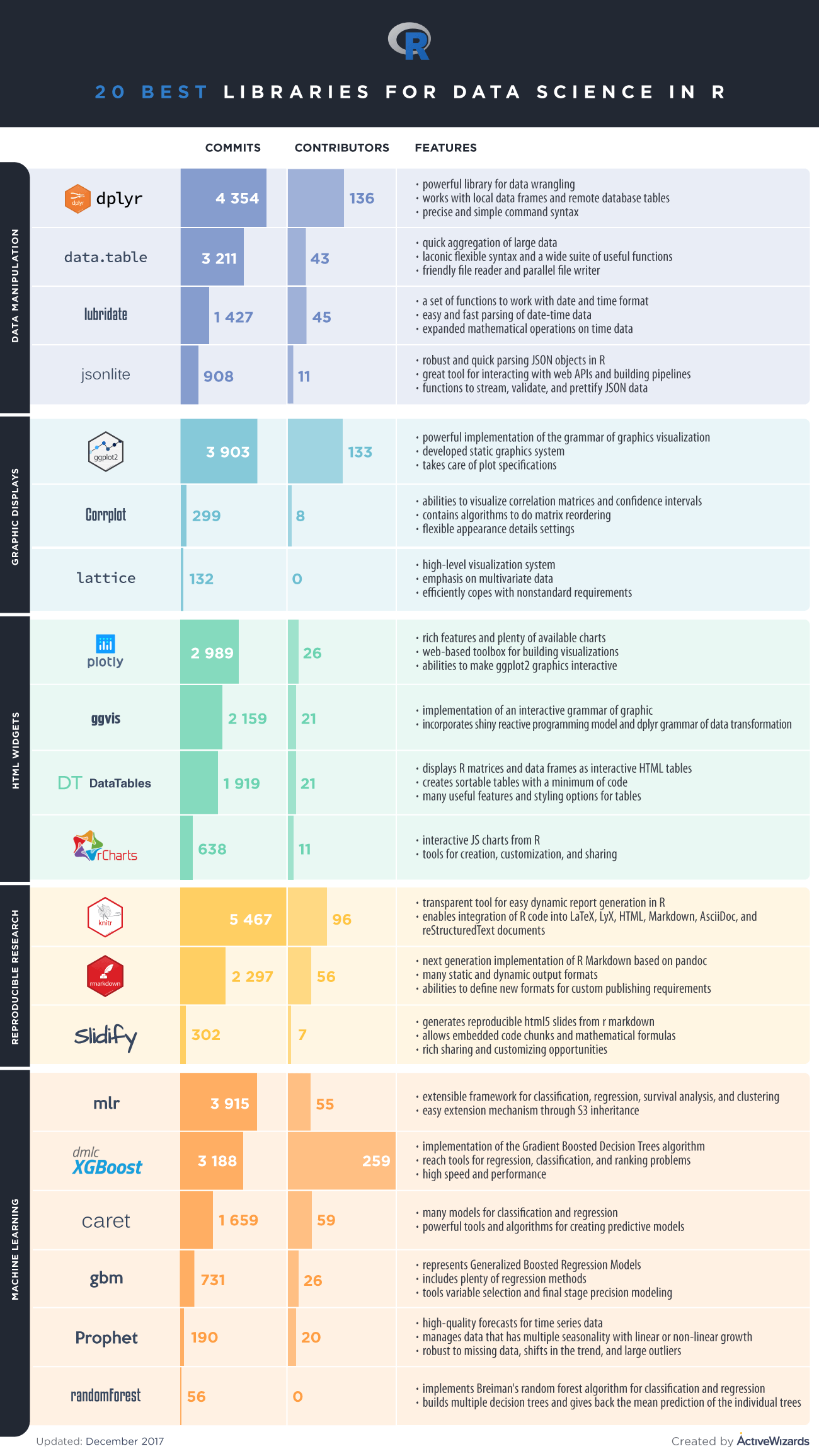
The 20 Packages That Still Matter Most
Core Data Work
dplyrfor filtering, joins, summarization, and transformationtidyrfor reshaping messy data into analysis-ready formdata.tablefor high-performance tabular work on larger datasetsreadrfor reliable ingestion of flat filesstringrfor practical string handlinglubridatefor date and time operations
Visualization and Communication
ggplot2for statistical graphics and repeatable chart designplotlyfor interactive visualsshinyfor internal analytical apps and lightweight dashboardssffor spatial analysis and mapping
Cleaning and Workflow Ergonomics
janitorfor quick cleanup of column names and basic data hygienebroomfor converting model results into tidy tablesdbplyrfor using familiar data manipulation syntax against databasesarrowfor columnar formats and faster interchange with modern data systems
Modeling and Machine Learning
tidymodelsfor a modern modeling workflow across preprocessing, tuning, and evaluationcaretfor teams maintaining older but still common training workflowsxgboostfor gradient-boosted trees on structured datarangerfor fast random forest workflowsglmnetfor regularized linear and logistic modeling
Production and Reproducibility
targetsfor reproducible pipelines and dependable analytical execution
How To Read This List
This is not a strict ranking. It is a practical shortlist organized by job.
- If your team does analytics and reporting, start with
dplyr,tidyr,readr,ggplot2, andlubridate. - If your team builds statistical or machine-learning workflows, add
tidymodels,glmnet,ranger, andxgboost. - If you care about reproducibility and delivery, add
targets,shiny,plotly, andarrow.
Where R Still Fits Best
R is especially strong when:
- analysts and statisticians are close to the business problem
- reproducible reporting matters
- the work depends on statistical depth more than application engineering
- visualization and exploratory analysis are central
Python remains the broader general-purpose ecosystem, but R is still extremely effective in the right hands and for the right workloads.
Infographic
Final Takeaway
The best modern R stack is not the longest list of packages. It is the smallest set your team can use consistently across wrangling, analysis, modeling, and delivery.
Need Help Choosing the Right Stack for Analytics or Statistical Modeling?
ActiveWizards helps teams choose practical tools for analytics, modeling, and production delivery so the stack fits the workflow instead of getting in its way.