The original infographic still works as a useful category map, but the way teams choose between Python, R, and Scala for data science is clearer now than it was in 2018.
Today the decision is less about which language is “best” and more about which environment matches the work:
Pythonis the broad default for machine learning, data engineering-adjacent analytics, and productizationRremains excellent for statistics, research workflows, and communication-heavy analytical workScalais most compelling when the surrounding platform is already JVM- and Spark-centered
INFOGRAPHIC
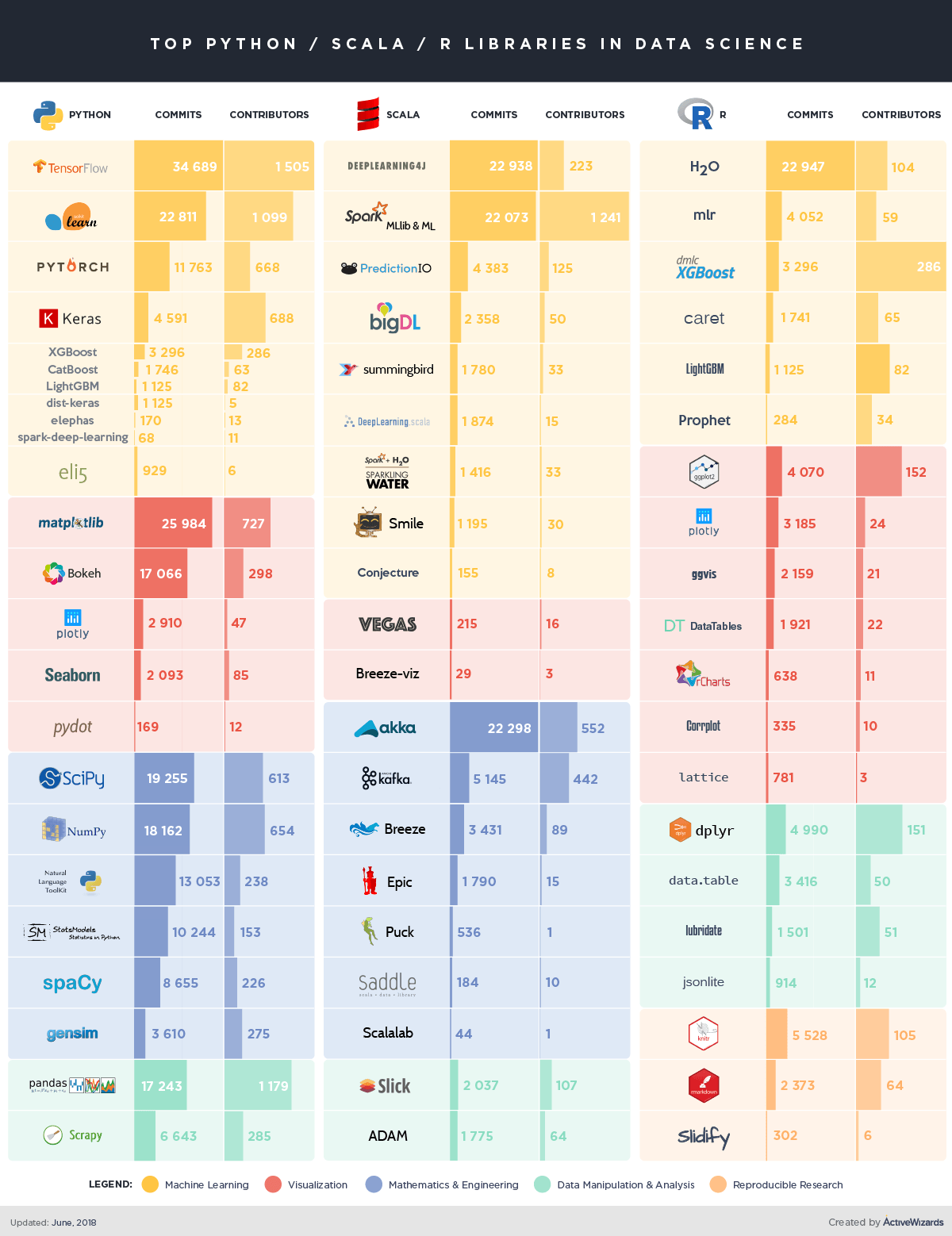
Python
Python became the default language for many modern data teams because it stretches across the full delivery path:
- exploratory analysis
- machine learning
- deep learning
- APIs and services
- automation and production support
That breadth is the real differentiator. A team can start in notebooks, move into repeatable pipelines, expose models behind services, and stay in one language for much of the journey.
Python is usually the best fit when:
- machine learning is central
- multiple teams need to collaborate across analytics and engineering
- the end state includes production services, orchestration, or applications
R
R remains deeply valuable, especially where statistical rigor and communication are the center of the workflow.
It still shines in:
- advanced statistics
- research and experimentation
- publication-quality analysis
- reproducible reporting
- specialized analytical domains with mature R packages
R is often strongest when analysts and researchers are the primary users and when the work benefits from a highly expressive statistical environment rather than a general-purpose programming language.
Scala
Scala is no longer the default entry point for most data science teams, but it still has a very real niche. It is strongest when data work is tightly coupled with JVM services, Spark-heavy data processing, or platform teams that already operate in the Java and Scala ecosystem.
Scala tends to make sense when:
- Apache Spark is a first-class platform choice
- the data team works closely with JVM application teams
- type safety and large-scale engineering practices matter more than notebook ergonomics
For many teams, Scala is less about experimentation speed and more about platform alignment.
A Practical 2026 Framing
If you are starting fresh, the default answer is usually:
- choose
Pythonfor the main delivery language - keep
Rwhere statistical depth and reporting justify it - use
Scalawhen the broader platform architecture already makes it the right operational choice
That is why many mature organizations are not “Python versus R versus Scala.” They are:
- mostly Python
- some R for specialist analytical work
- some Scala inside platform or Spark-heavy systems
Final Takeaway
Languages matter, but the larger decision is organizational:
- who writes the analysis
- who deploys the outputs
- what infrastructure already exists
- how much of the work needs to survive beyond notebooks
The strongest teams usually standardize where they can, but they do not force every problem into one language when the workflow says otherwise.
Need Help Standardizing a Data Team Stack Without Slowing Delivery?
ActiveWizards helps teams choose the right mix of languages, libraries, and data platform patterns so analytical work can move cleanly into production.